What is Predictive Maintenance?

Overview
Predictive maintenance combines data about hardware, software, and service components in order to determine the maintenance requirements for mechanical assets. Monitoring emerging failures, predicting capacity overruns, identifying breakdowns, and determining remaining asset life are all aspects of predictive maintenance. AIOps, the use of Artificial Intelligence for IT Operations, is sometimes used for predictive maintenance.
Anticipating and preparing for failure has long been a fact of life for mechanical operations. Until recently, routine replacement of a part after a specified time was the most common form of avoiding a part’s failure in service. This form of scheduled preventive maintenance is helpful. But not all parts fail at the same rate, and premature replacement is waste based on averages and approximation. Moreover, a system that relies on scheduled maintenance alone will not detect actual or imminent failure of a part that’s prematurely defective. Another strategy for reducing downtime was to replace all the parts when one failed, and it was unclear which one, but this strategy has a clear high-cost downside.
Predictive Maintenance
What makes predictive maintenance so important?
There are other benefits as well. Depending on the industry, contractual service level agreements (SLAs) may require organizations to maintain delivery of service or materials on a strict 24×7 basis, or face penalties and even fines. In other cases, equipment failure can cause a loss of revenue because of interruptions to supply chains, loss of inventory, customer churn, and other obvious consequences owing to operational slowdown. Predictive maintenance can help mitigate all of these potential consequences of system downtime.
The use of statistical analysis, sensor monitoring, advanced analytics, and AI to more accurately predict when a failure will occur offers a great improvement. With sensors continually monitoring the health of each part, a monitoring system can alert you in advance of a failure. This is the core benefit of putting a predictive maintenance program in place: you replace only near-defective parts, thus saving labor and the expense of unnecessary parts replacement while maintaining high uptime. Plus, a good predictive maintenance system gives you time to schedule maintenance at the least disruptive time for the business.
Predictive maintenance challenges
Big data techniques involving machine learning and the processing of very large data sets have evolved for minimizing downtime and MTTR (mean time to recovery). And while these benefits are clear, there are a number of challenges modern organizations face, including:
Data-intensive processes
The need to train and maintain ML models on long-term historical data at high scale can be daunting for most analytical databases on the market.
Disparate data storage
Accurate machine learning and other forms of analysis to identify failure patterns all require access to remote data silos, and/or process data. Aggregating data of different types, or even data of similar, but not identical types – like time series data from two devices taken at different intervals – can be time consuming and challenging.
Difficulties in operationalizing ML
The complexities of data science and lack of specialized knowledge can hamper a team’s ability to use machine learning as a critical capability in the predictive maintenance toolbox.
False positives
When rules for a failure alert are too rigid, or model patterns are too restrictively defined, a large number of alerts can be generated that don’t actually require action. This can cause alert fatigue. Being able to revise and continually improve predictions is an important aspect of predictive maintenance.
Simplify business operations and create customer value
-
Reactive maintenance
System problem
Customer call
Dispatch
Onsite trouble shooting
Parts delivery
Repair or replace
System functional -
Predictive maintenance
Remote monitoring predicts potential failure
Service scheduled
Problem avoided
How OpenText™ Analytics Database puts predictive maintenance to work
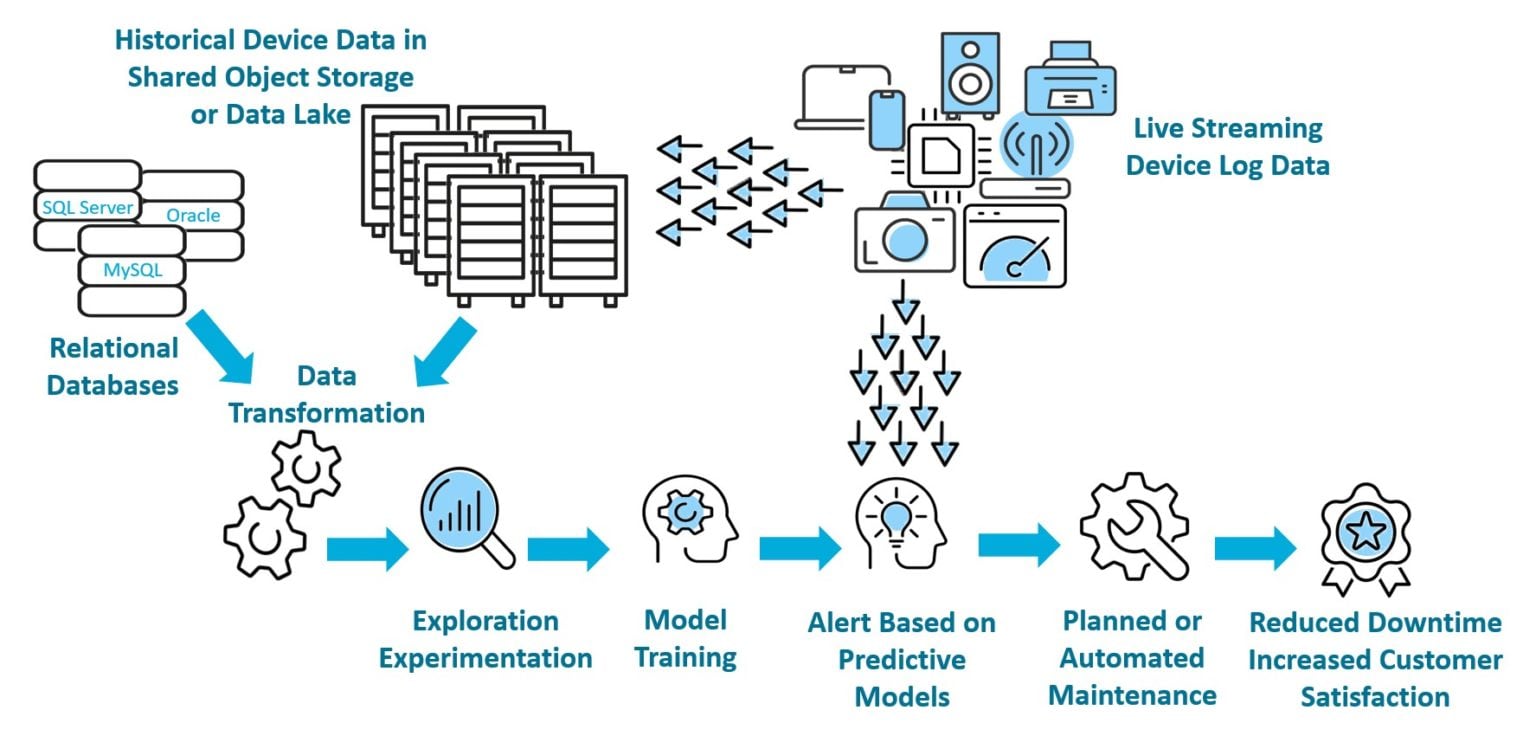
OpenText™ Analytics Database can continuously monitor even extremely large data sets from equipment components as the data are generated. If a simple statistical analysis is sufficient, that analysis can be done easily and rapidly in a database. OpenText Analytics Database has over 650 built-in functions that can do fast analysis of many kinds that are useful for predictive maintenance, such as time series analysis, event pattern matching, and machine learning.
When machine learning is used to do predictive maintenance, then data such as maintenance logs and any sensor information that has been collected over years is accumulated in a data store such as on a file system like HDFS, or an object storage location such as S3. A machine learning model is trained on that data, to identify the patterns that indicate a potential problem. Then, new, current data is streamed in from devices and their components and is checked by that trained model. An alert is sent when a potential problem is identified. Remedial action is planned and taken BEFORE a failure occurs.