OpenText Core Capture
インテリジェントなコンテンツキャプチャでクラウドドキュメント処理を自動化
OpenTextがインテリジェントドキュメント処理におけるリーダーに選出IDCによるレポートの抜粋を入手する
概要
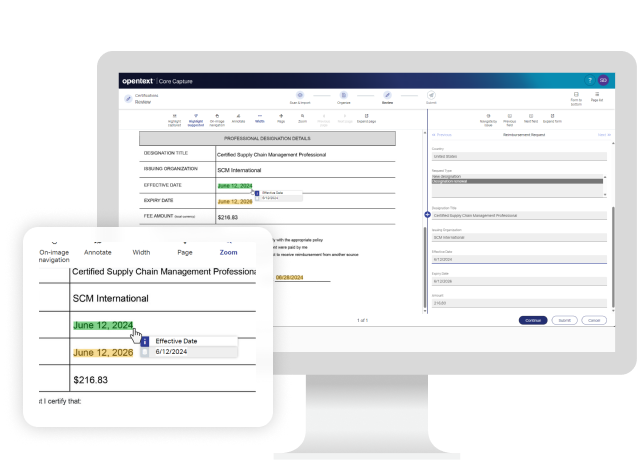
OpenText Core Captureがビジネスにもたらすメリット
OpenText Core Captureを活用するメリットをご紹介します。
-

SaaSでIT負担を軽減
簡素化されたデプロイメントと自動化されたソフトウェアアップグレードにより、ITリソースを解放します。
-

部門や場所を超えた情報取得の一元化
キャプチャと共有サービスを拡張し、紙、メール、PDF、画像などで届く情報を自動的に抽出することで、組織全体のコンテンツをサポートします。
-

従業員の生産性を向上させる
自動化とシンプルなユーザーインターフェースでワークフローを最適化し、従業員の効率と満足度を最大化します。
-

コンプライアンスとドキュメントアクセスの簡素化
半構造化・非構造化コンテンツから抽出したメタデータをもとに、文書を自動的に分類・ファイリングすることで、情報ガバナンスを強化します。
OpenText Core Captureが選ばれる理由
-
継続的な機械学習
認識モデルを手動でトレーニングし、定期的に更新する必要がないため、セットアップとメンテナンスのコストを削減できます。
-
複数の認識技術
ドキュメントタイプを識別し、テキストを分析してコンテキストを理解するマルチエンジンアプローチにより、ドキュメントとデータを使用可能にし、効率的なプロセスを実現します。
-
ヒューマン・イン・ザ・ループ検証
継続学習エンジンに自動的にフィードされるシンプルなWeb UIをレビュアーに提供することで、精度を向上させ、継続的なメンテナンスを削減します。
主な機能
-
インテリジェントな文書の分類
テキストとグラフィックを組み合わせた複数の分類技術(特許取得済み)に基づいて文書を自動的に識別し、単一の技術だけでは実現できない高精度かつ高速なパフォーマンスを実現します。
-
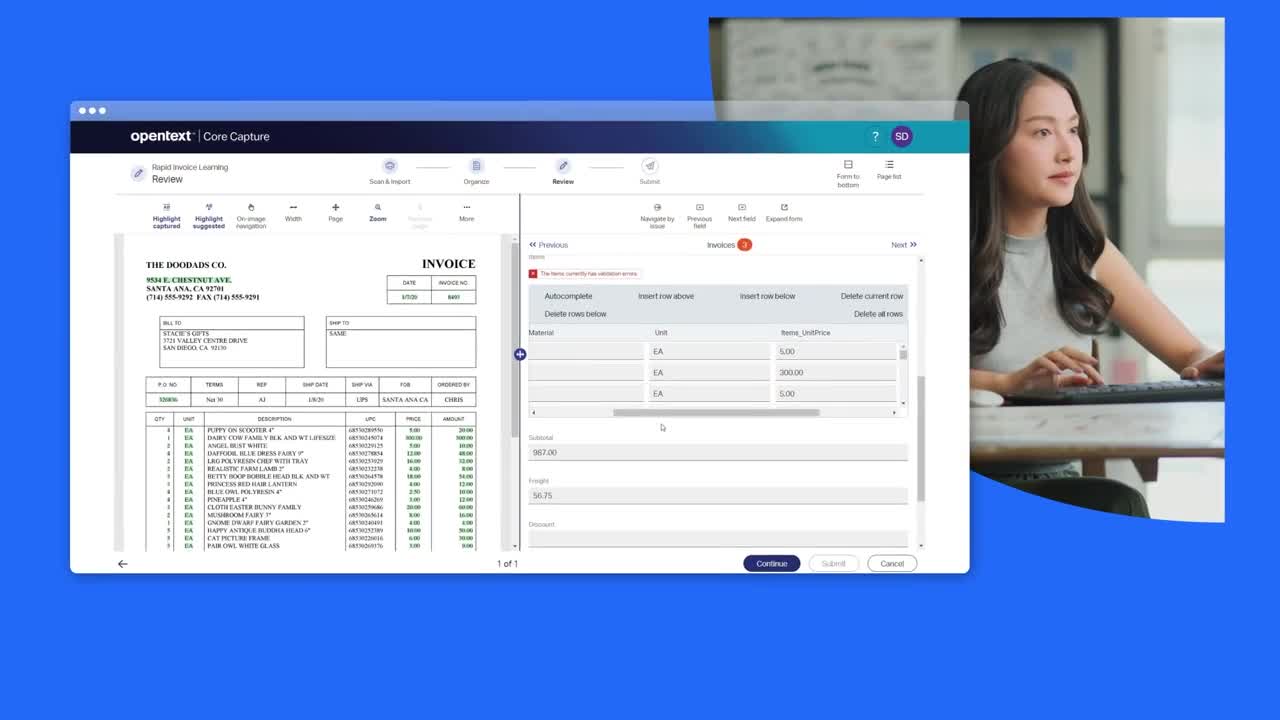
インテリジェントなデータ抽出と検証
組み込みの OCR、継続的な機械学習、および 85 言語にわたる OCR 精度の最適化に役立つサードパーティエンジンとの統合を活用することにより、他のビジネス システムに配信される情報の精度が向上します。
-
SaaS展開
OpenTextがホスティングするスケーラブルなプラットフォームでキャプチャ業務を管理し、北米、欧州、アジア太平洋地域のデータレジデンシーオプションを活用できます。
-
データ型ハイライトによるシングルクリック入力
ユーザーが正しいデータをより速く簡単に選択できるように、フィールドの可能な選択肢を強調表示し、選択したテキストでメタデータフィールドを自動入力します。
-
設定可能なキャプチャワークフロー
ビジネス要件を満たすワークフローを設計することができます。レビュアーの追加やバックグラウンド処理の許可など、ワークフローテンプレートはシンプルなノーコードモデラーを使用して作成することができます。
-
複数のエクスポートオプション
OpenText™ Core Content Management、OpenText™ Content Management、OpenText™ Documentum™ Content Management、OpenText™ Capture、CMISを使用するその他の基幹業務ソリューションなど、複数のアプリケーションとデータを共有します。
ご購入
OpenText Core Capture
| スワイプして詳細を見る |
紙媒体やデジタル媒体のコンテンツをアクション可能なデータに変換し、精度と効率を高めます。
| 複数の認識技術 |
|---|
| オムニチャネルコンテンツの取り込み |
正確に抽出されたデータに基づいてドキュメントを自動的に分類し、ファイリングします。
| インテリジェントなドキュメントの分類 |
|---|
| ドキュメントの分類 |
| 設定済みのドキュメントタイプ |
OCR、AI、機械学習が組み込まれているため、85の言語とロケールで手作業によるデータ入力が最小限に抑えられ、正確性が確保されます。
| 継続的な機械学習 |
|---|
| 統合された大規模言語モデル |
| AI・機械学習の統合 |
| センチメント分析によるAIの拡張 |
継続学習エンジンに自動的にフィードされるシンプルなUIをレビュアーに提供することで、精度を向上させます。
| レスポンシブWebクライアント |
|---|
| 高速デスクトップクライアント |
| シングルクリックエントリ |
| テーブルのオートコンプリート |
| 外部データベース検索 |
テキスト検索可能でメタデータが豊富なファイルが確実に利用できるようにし、時間や場所を問わず顧客や従業員が情報を参照できるようにします。
| OpenText用ビルトインエクスポーター |
|---|
| CMISおよびSFTP経由でのエクスポート |
テクノロジーを活用して効率的なプロセスを実装し、ユーザーの介入なしに反復タスクを実行します。
| 自動的にルーティングされる情報 |
|---|
| 設定可能かつシンプルなキャプチャワークフロー |
| 設定可能かつ複雑なキャプチャワークフロー |
ERP、CRM、基幹業務アプリケーションにインテリジェントな情報キャプチャ機能とデータ抽出機能を追加します。
| 外部アプリからのキャプチャの呼び出し |
|---|
| アドオン Salesforce® |
| アドオン SAP Solutions |
| オフクラウド |
|---|
| パブリッククラウド |
| プライベートクラウド |
| マネージドサービス |
OpenText Core Captureの価値を高める
導入
パブリッククラウドSaaSのセキュリティと拡張性の中で、コンテンツをデジタルビジネスにつなげます。
- すぐに使えるSaaSアプリケーションでデジタルトランスフォーメーションを加速化OpenTextのパブリッククラウド
- 情報管理能力の開発、接続、拡張OpenText Developer CloudからのAPI
プロフェッショナルサービス
OpenText Professional Servicesは、エンドツーエンドのソリューション導入と包括的なテクノロジーサービスを組み合わせて、システムの改善を支援します。
- 信頼できるパートナーに情報管理を導いてもらう成功への道のり
- 最新のソリューションでビジネスを未来へ推進次世代のサービス
- 情報管理の過程を加速させる コンサルティングサービス
- 情報管理ソリューションの可能性を最大限に引き出すカスタマーサクセスサービス
パートナー
OpenTextは、お客様が適切なソリューションやサポート、そして期待通りの結果を得られるよう支援します。
- OpenTextのパートナーディレクトリを検索パートナーを探す
- OpenTextの製品とソリューションを強化する、業界をリードする組織戦略的パートナー
- OpenTextのパートナーソリューションカタログを見るアプリケーションマーケットプレイス
トレーニング
OpenText Learning Servicesは、知識とスキルを加速させるための包括的なイネーブルメントと学習プログラムを提供します。
- 効果的な導入のため、あらゆるユーザーの要求にお応えしますラーニングサービス
- ニーズに合わせてパーソナライズされたレベルのトレーニングに無制限にアクセスラーニングサブスクリプション
コミュニティ
OpenTextのコミュニティをご利用ください。個人や企業とつながり、インサイトやサポートを得ることができます。ディスカッションに参加する。
- アイデアを探求し、ディスカッションとネットワークに参加OpenText Core Captureフォーラム
プレミアムサポート
複雑なIT環境に対応したミッションクリティカルなサポートを提供する専任の専門家が、OpenTextのソリューションの価値を最適化します。
- 技術および戦略的専門家による1対1の個別支援プレミアムサポート
OpenText Core Captureのリソース
OpenText Core Capture
Read the overviewContinuous machine learning: Your AI edge
Read the position paperBuyer’s guide to intelligent content
Read the guideOpenText Core Capture
Read the overviewContinuous machine learning: Your AI edge
Read the position paperBuyer’s guide to intelligent content
Read the guideWhat’s new in OpenText Core Capture
Read the blogOpenText named a leader in the Infosource Global Capture and IDP Vendor Matrix
Read the blogWhat is intelligent document processing?
Read the blogTake control of your content with OpenText Core applications
Read the blogIt’s not just about going paperless
Read the blogKeep customer data streams clean with cloud capture from OpenText
Read the blogWhat’s new in OpenText Core Capture
Read the blogOpenText named a leader in the Infosource Global Capture and IDP Vendor Matrix
Read the blogWhat is intelligent document processing?
Read the blogTake control of your content with OpenText Core applications
Read the blogIt’s not just about going paperless
Read the blogKeep customer data streams clean with cloud capture from OpenText
Read the blog
Leverage continuous machine learning to capture and extract data
Watch the video
Capture and intelligently file HR documentation for easy onboarding
Watch the video
Improve workflow and experiences with OpenText cloud capture service
Watch the video
Make customers and employees happy with OpenText Cloud Capture
Watch the video