OpenText 被评为智能文档处理领域的领导者获取IDC 报告摘录
OpenText Core Capture 如何使企业受益
了解使用OpenText CoreCapture 的优势。
-

利用 SaaS 减轻 IT 负担
通过简化部署和自动软件升级,释放 IT 资源。
-

跨部门和跨地点统一信息采集
通过自动提取以纸张、电子邮件、PDF 和图像形式发送的信息,扩大采集和共享服务的规模,为整个组织的内容提供支持。
-

提高员工生产力
利用自动化和简单的用户界面优化工作流程,最大限度地提高员工效率和满意度。
-

简化合规性和文件访问
根据从半结构化和非结构化内容中提取的元数据,自动对文件进行分类和归档,从而加强信息管理。
为什么选择OpenText CoreCapture ?
-
持续机器学习
无需手动训练和定期更新识别模型,从而降低设置和维护成本。
-
多种识别技术
多引擎方法可识别文档类型并分析文本以了解上下文,从而确保文档和数据可随时使用并实现高效流程。
-
人在环验证
通过为审稿人提供一个简单的网络用户界面,自动输入持续学习引擎,提高准确性并减少持续维护。
主要特点
-
智能文件分类
基于多种专利分类技术自动识别文档,这些技术结合了文本和图形方法,与仅使用单一技术相比,具有更高的准确性和更快的性能。
-
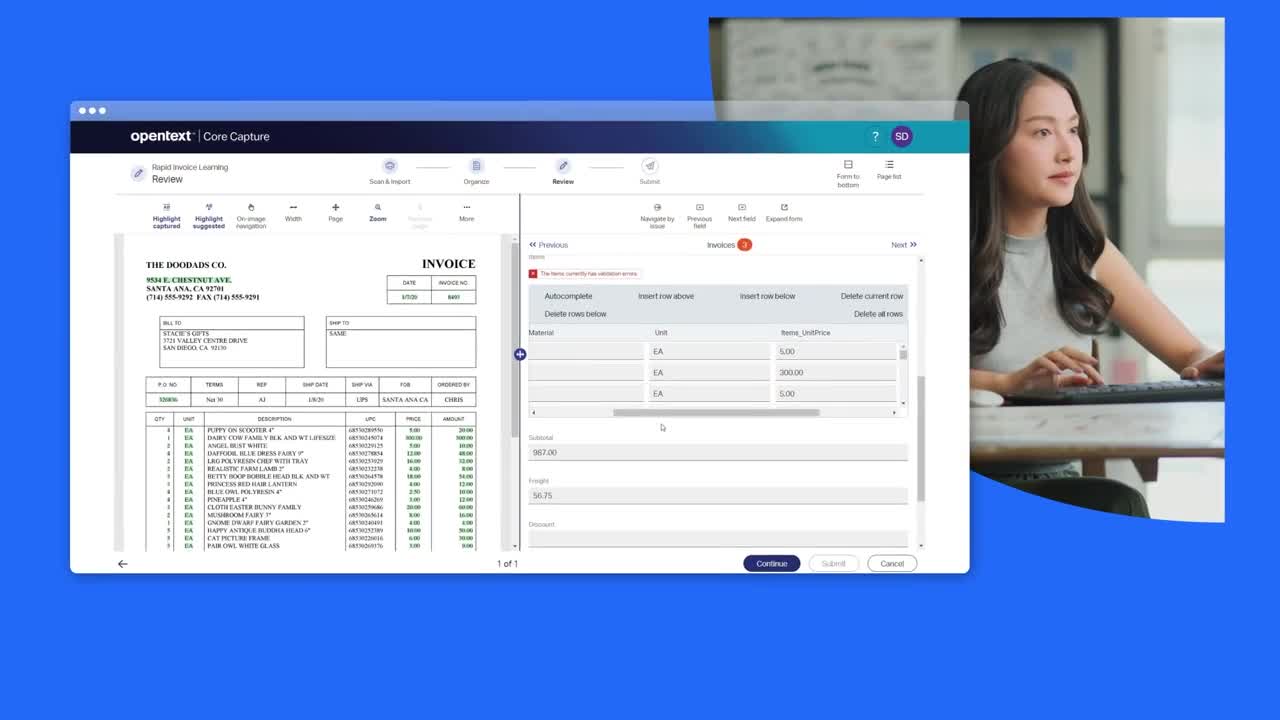
智能数据提取和验证
利用内置 OCR、持续的机器学习以及与第三方识别引擎的集成,帮助优化 85 种语言和地区的 OCR 准确性,从而提高传送到其他业务系统的信息的准确性。
-
SaaS 部署
通过OpenText 托管的可扩展平台管理采集业务,数据驻留地可选择在北美、欧洲和亚太地区。
-
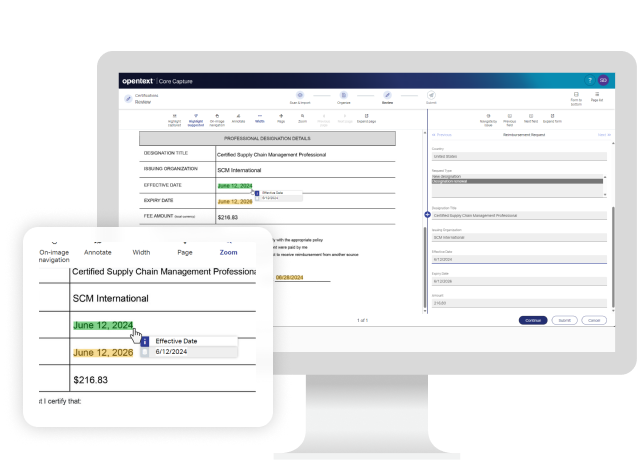
单击输入,数据类型高亮显示
突出显示字段的可能选项,让用户更快、更容易地选择正确的数据,然后利用预设规则自动填充元数据字段,确保提取正确的数据。
-
可配置的采集工作流程
使用户能够设计工作流程以满足业务需求。无论是添加额外的审核人员还是允许后台处理,都可以使用简单的无代码建模器创建工作流程模板。
-
多种导出选项
与多个应用程序共享数据,包括 OpenText™ Core Content ManagementOpenText™ Content Management, OpenText™ Documentum™ 内容管理、 OpenText™ Capture以及使用 CMIS 的其他业务线解决方案。
如何购买
OpenText Core Capture
| 轻扫查看更多 |
将纸质和数字内容转化为可操作的数据,提高准确性和效率。
| 多种识别技术 |
|---|
| 全渠道内容摄取 |
根据准确提取的数据自动对文件进行分类和归档。
| 智能文件分类 |
|---|
| 文件分隔 |
| 预配置文档类型 |
通过内置 OCR、人工智能和机器学习,最大限度地减少人工数据输入,并确保 85 种语言和本地语言的准确性。
| 持续机器学习 |
|---|
| 综合大型语言模型 |
| 集成人工智能和机器学习 |
| 通过情感分析扩展人工智能 |
为审稿人提供简单的用户界面,并自动输入持续学习引擎,从而提高准确性。
| 响应式网络客户端 |
|---|
| 高速桌面客户端 |
| 单击输入 |
| 表格自动完成 |
| 外部数据库查询 |
确保提供可搜索文本、元数据丰富的文件,以便随时随地为客户和员工提供信息。
| 内置出口程序,用于OpenText |
|---|
| 通过 CMIS 和 SFTP 导出 |
利用技术实施高效流程,在无需人工干预的情况下执行重复性任务。
| 自动路由信息 |
|---|
| 可配置的简单采集工作流程 |
| 可配置的复杂采集工作流程 |
在企业资源规划、客户关系管理和业务应用中增加智能信息采集和数据提取功能。
| 从外部应用程序调用捕捉功能 |
|---|
|
附加
Salesforce®
|
|
附加
SAP 解决方案
|
| 离云 |
|---|
| 公共云 |
| 私有云 |
| 托管服务 |
加速实现OpenText Core 的价值Capture
部署
利用公共云 SaaS 的安全性和可扩展性,将内容与数字业务连接起来。
- 利用即用型 SaaS 应用程序加速数字化转型OpenText 公共云
- 开发、连接和扩展您的信息管理能力来自OpenText Developer Cloud 的应用程序接口
专业服务
OpenText 专业服务将端到端的解决方案实施与全面的技术服务相结合,以帮助改进系统。
- 让值得信赖的合作伙伴为您指引信息管理之路您的成功之路
- 用现代解决方案推动您的企业迈向未来下一代服务
- 加速您的信息管理之旅 咨询服务
- 释放信息管理解决方案的全部潜能客户成功服务
合作伙伴
OpenText 帮助客户找到正确的解决方案、正确的支持和正确的结果。
- 搜索OpenText 合作伙伴目录寻找合作伙伴
- 行业领先的组织机构可增强OpenText 产品和解决方案的功能战略合作伙伴
- 浏览OpenText 合作伙伴解决方案目录应用市场